
はじめに
前回の記事でPythonの機械学習ライブラリの超定番であるscikit-learnでとりあえずデータを読み込むところまでご紹介しました。そして読み込んだデータをpndasのデータフレームにとりこんでデータの概要を確認することが出来ました。
今回は、取り込んだデータをmatplotlibというグラフ表示用のモジュールを使ってグラフ表示してみましょう。matplotlibも様々なグラフを用いてデータを視覚化する定番のモジュールです。データ分析の前に傾向を把握しておくことはとても大事なことです。
とても良くできたライブラリなので、手順はそれほど複雑では有りません。では内容を確認しましょう!
※本記事の内容を実機で試してみたいという方は以下の記事を参考に開発環境をご準備ください
・Pythonやるならド定番!Anacondaをサクッと入れて巨人の肩に乗りましょう!
・Win10&Anaconda3環境でJupyter Notebookを起動してプログラムを実行する方法
・個人情報保護方針及び免責事項
matplotlibでグラフ化してみる本記事の目的
本記事ではデータをまずはグラフにする手順をご紹介します。グラフも棒グラフや折れ線グラフなどと言ったものがありますが、データの傾向を掴むには役に立つものです。今回は紹介しませんが、matplotlibにはデータを三次元グラフ化する機能も有り、データの可視化に優れた特性があります。
自分でデータを分析する分にはそれほど立派な可視化(ビジュアライゼーション)は必要とされないかもしれませんが、その一方で人に説明する際はデータのわかりやすい可視化は昨今では必須と言ってもいい状態になってきました。
matplotlibをつかったデータビジュアライゼーションになれておくと、あとあと有益だと思います。
matplotlibでグラフ化する処理の流れ
それでは処理の流れを説明します!
scikit-learnのデータをpandasのデータフレームに取り込む
これは前回ご説明したとおりです。

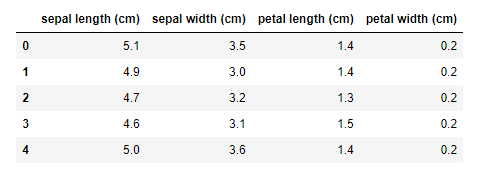
ちなみにデータの内容はこんな感じです。
グラフ化する項目をリストで指定、描画域を調整してグラフを表示する
columns_nに表示する項目のリストを格納します。今回は4項目しかないのですべて表示します。

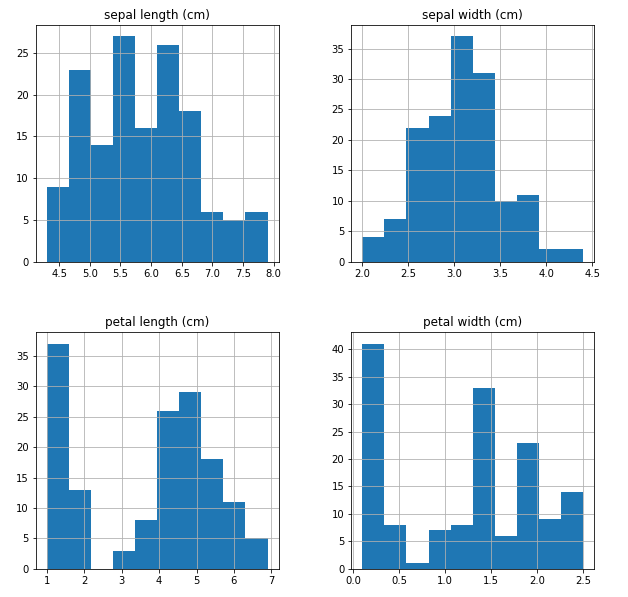
表示結果は以下になります。
matplotlibでグラフ化するサンプルコード
それではサンプルコードです!
# サンプルデータの読み込み from sklearn.datasets import load_iris iris = load_iris() # データフレームに読み込み import pandas as pd df = pd.DataFrame(iris.data, columns=iris.feature_names) import matplotlib.pyplot as plt # グラフ化する項目(数値) columns_n = ['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)'] # 描画領域の調整 plt.rcParams['figure.figsize'] = (10, 10) # ヒストグラム表示 df[columns_n].hist() plt.show()
おわりに
matplotlibでグラフを表示する方法をご説明しました。使用法に関しては様々あります。そのすべてをご紹介するには一冊の本になってしまいますので割愛いたしますが、参考までにリンクと参考書籍をご案内いたします。
・matplotlib.org/Usage Guide
・Matplotlib&Seaborn実装ハンドブック (Pythonライブラリ定番セレクション)



