はじめに
前回までで機械学習用のデータを読み込んでデータフレームに取り込み、様々なライブラリでデータの可視化をすることが出来ました。ここまでくれば、あとはついに機械学習でデータを分析するだけというところまで来ることが出来ました!
今回は、scikit-learnのiris(あやめ)のデータを使ってロジスティクス回帰による分類問題を解いてみましょう!突然ロジスティクス回帰とか分類問題などと言われても何のことやらわからないかもしれませんが、ご安心ください!とりあえず難しいことはおいておいて、早速コードを動かしてみましょう!
※本記事の内容を実機で試してみたいという方は以下の記事を参考に開発環境をご準備ください
・Pythonやるならド定番!Anacondaをサクッと入れて巨人の肩に乗りましょう!
・Win10&Anaconda3環境でJupyter Notebookを起動してプログラムを実行する方法
・個人情報保護方針及び免責事項
scikit-learnでロジスティック回帰の目的
本記事ではscikit-learnのiris(あやめ)のデータを使ってロジスティクス回帰による分類問題を解いてみます。とりあえず問題を解くにあたって諸概念を概観しておきましょう。
ロジィステック回帰とは
ベルヌーイ分布に従う変数の統計的回帰モデルの一種である。連結関数としてロジットを使用する一般化線形モデル (GLM) の一種でもある。
ロジスティック回帰
数学的な厳密性を強調した非常に複雑な表現です。これでは何のことかよくわからないと思いますので、誤解を恐れずにカンタンに説明すると、
「与えられたデータを分類する境界線を見つけ出す」
ということになると思います。例えば二次元のデータを考えたときに、存在しているデータから境界線を探します。下記の画像のようなイメージです。
wikipediaより
分類問題とは
分類の目的は、データが属するクラス(犬 or 猫など)を予測することです。
予測するクラス数が2クラスの場合、2値分類と呼ばれます。
具体例として、個人ローン審査の場合、取引情報や個人信用情報などを入力とし、その人に融資を承認するか否かかを予測します。
分類と回帰
上記引用の例がわかりやすいのですが、例えば2クラスの犬か猫の場合、大きさや体重で分類することができるでしょう。この大きさ、体重というのが説明変数と呼ばれ、犬か猫かを識別する境界を探すのがロジスティクス回帰による学習ということになります。
なんとなくイメージが掴めたでしょうか?
本記事で行うロジィステック回帰にる分類問題
本記事ではscikit-learnのiris(あやめ)のデータを使ってロジスティクス回帰による分類問題を解いてみます。これはあやめの「種類」をデータの中にある花弁とがくの長さと幅という4つの数値の中から代表的な変数を選んで分類します。
以下に手順とソースコードを示しますので、参考にしながら理解を深めてください。
scikit-learnであやめの種類を分類する処理の流れ
それでは処理の流れを説明します!
あやめのデータの必要な部分を読み込んで、説明変数に当たりをつける
seabornライブラリの機能を使ってirisデータを読み込みます。その際に、今回は簡略化のため2値分類としますので、読み込むあやめの種類はversicolorとvirtinicaの2種類とします。

読み込んだら散布図でどのデータが分類のための説明変数としてふさわしいか見てみましょう。
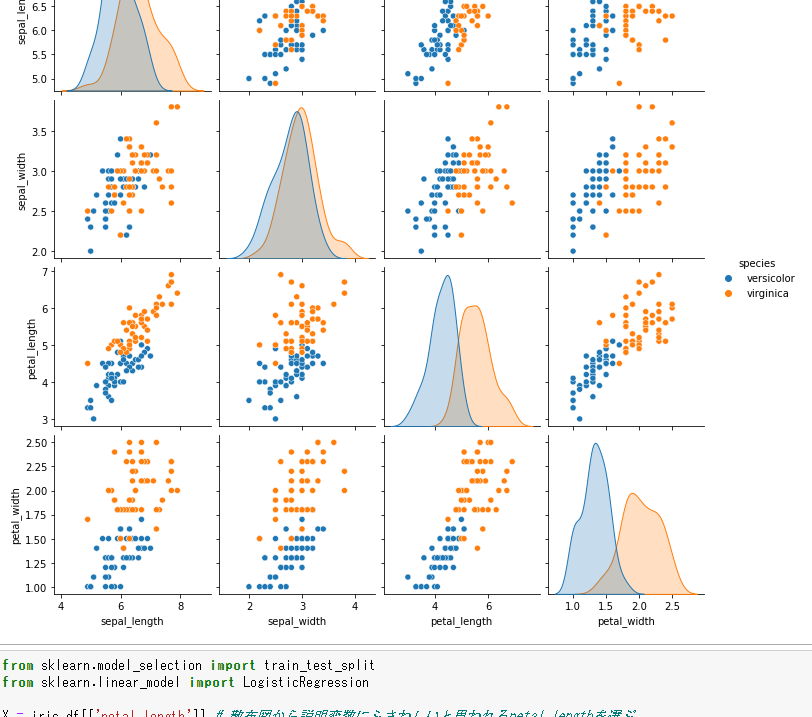
上から三段目のpetal_lengthを見ると、2つの種類の分かれ目が比較的はっきりしているのがわかります。
説明変数と目的変数を用意し、学習データと検証データに分けて学習
petal_lengthを説明変数とし、またあやめの種類を目的変数にしてデータを整理します。その後、train_test_split関数を使って学習データと検証データにデータを分割します。なれないとよくわからないかもしれませんが、こうした記法を用いることでデータを学習用と検証用に分けています。

その後、logistics回帰のインスタンスを生成し、.fitで学習を行います。拍子抜けするほどカンタンなコードですが、これで学習できています。引数にX_train,Y_trainの学習データを与えている点に注目してください。
学習結果の確認・精度検証
学習結果を検証します。テストデータの最初の10行と、学習結果(y_pred)の最初の10行を比較してみましょう!左から三番目の数値が非整合ですが、残りは合っています。
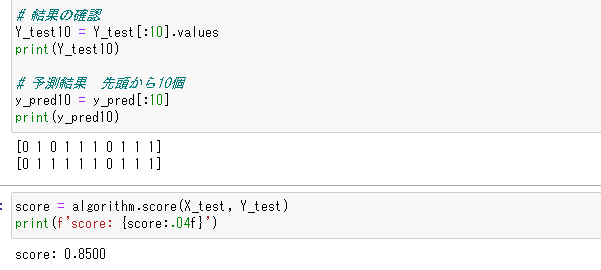
また.score関数でモデル全体の精度を検証することも出来ます。今回は0.85の精度となっています。
scikit-learnであやめの種類を分類するサンプルコード
それではサンプルコードです!上記の処理の流れで分割したコードを以下に示します。
あやめのデータの必要な部分を読み込んで、説明変数に当たりをつける
import seaborn as sns
iris_df = sns.load_dataset('iris') # データセットの読み込み
iris_df = iris_df[(iris_df['species']=='versicolor') | (iris_df['species']=='virginica')] #versicolorとvirginicaに限定して読み込み
import matplotlib.pyplot as plt
sns.pairplot(iris_df, hue='species')
plt.show()
説明変数と目的変数を用意し、学習データと検証データに分けて学習
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X = iris_df[['petal_length']] # 散布図から説明変数にふさわしいと思われるpetal_lengthを選ぶ
Y = iris_df['species'].map({'versicolor': 0, 'virginica': 1}) # versicolorをクラス0, virginicaをクラス1とする
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0) # 学習データと検証データを8:2に分ける
algorithm = LogisticRegression() #ロジスティック回帰モデルのインスタンスを生成
algorithm.fit(X_train,Y_train) # 学習
y_pred = algorithm.predict(X_test)
# 結果の確認
Y_test10 = Y_test[:10].values
print(Y_test10)
# 予測結果 先頭から10個
y_pred10 = y_pred[:10]
print(y_pred10)
学習結果の確認・精度検証
score = algorithm.score(X_test, Y_test)
print(f'score: {score:.04f}')
おわりに
本記事では、Pythonの機械学習ライブラリであるscikit-learnでロジスティック回帰を行ってみるカンタンな手順をご紹介しました。ところどころ難しい部分もあったと思いますが、コード自体はさほど長くなく、全体としての処理はカンタンだったのではないかと思います。
本格的な機械学習を行おうとする場合、今回と異なり分類するクラスが2以上になったり、説明変数が複数になったり、といったことが起きます。その場合はモデルを選び直したりしなければならないのですが、基本的には分類をする場合は今回の考え方が基本となります。
次回以降、より高度な機械学習のアルゴリズムに挑戦していきたいと思っております。