はじめに
前回までにpythonからExcelファイルを使う方法としてOpenPyXlをご紹介し、PDFを扱う方法としてPdfMinerをご紹介しました。Pythoの強力なライブラリを使うことで、これらの形式のファイルの内容を取得し、結果を出力画面に表示するところまでできるようになりました。
しかし、出力をプログラムの出力先(本ブログではJuputerNoteBookを使っていますので、その出力画面)ではなくファイルとして保存しておくことができたら便利だと思わないでしょうか。とくにテキストファイルであれば汎用性のある文字情報として内容を記録しておくことができそうです。
本記事ではPythonのファイル書き込み機能を使って、ExcelやPDFから取得した内容をテキストファイルに記録する方法をご紹介します。内容の取得は前回までと同じですので、ファイルへの書き込み方法に特に気をつけてプログラムをご紹介します。
PythonでExcelやPDFの内容をテキストに記録する本記事の目的
OpenPyXlやPDFMierを使うことで、ExcelやPDFの内容を取得することはできます。これらの内容を汎用性のあるテキストファイルに保存することが本記事の目的です。テキストファイルであれば、その編集は比較的簡単ですし、高度な方法を考えれば、自然言語処理などのもとになるデータとすることができます。
本記事の内容をベースに、より高度なプログラミングの橋渡しとしてください。
PythonでExcelやPDFの内容をテキストに記録する処理の流れ
それでは処理の流れを説明します!
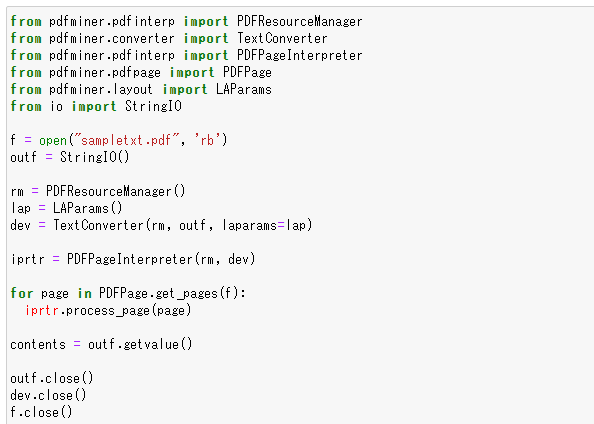
PDFMinerを使って内容を取得する
本記事ではPDFからテキストデータを取得して、テキストファイルに記録する方法をご紹介します。まずは前回の記事同様にPDFMinerを使って内容を取得しましょう!
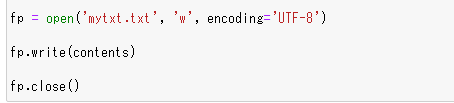
PythonのOpenメソッドを使い記録するテキストファイルを開く
Openメソッドを使います。第2引数を”w”と指定してありますが、これは書き込みモードで開くことを意味します。第3引数は文字コードをUTF-8に指定しています。
その他モード指定などは一度リファレンスをご確認ください。
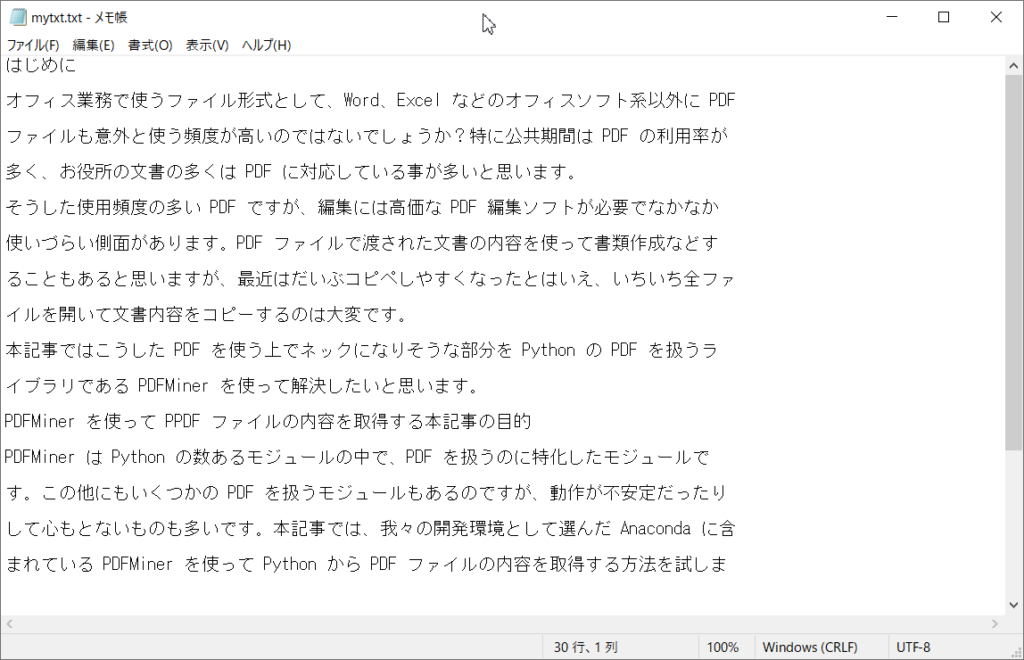
実行すると用意したテキストファイルにPDFの内容が書き込まれました。
PythonでExcelやPDFの内容をテキストに記録するサンプルコード
それではサンプルコードです!
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.layout import LAParams
from io import StringIO
f = open("sampletxt.pdf", 'rb')
outf = StringIO()
rm = PDFResourceManager()
lap = LAParams()
dev = TextConverter(rm, outf, laparams=lap)
iprtr = PDFPageInterpreter(rm, dev)
for page in PDFPage.get_pages(f):
iprtr.process_page(page)
contents = outf.getvalue()
outf.close()
dev.close()
f.close()
fp = open('mytxt.txt', 'w', encoding='UTF-8')
fp.write(contents)
fp.close()
おわりに
本記事ではPDFのテキストデータを扱いましたが、基本的にはExcelでも同じで、OpenPyXlで取得した内容をOpen()関数とWriteメソッドで書き込んでいく流れとなります。シンプルな処理ですが、例えば大量のPDF文書などから自然言語処理の元データを起こしたりする場合に重宝するのではないでしょうか?