はじめに
Pythonの機械学習モジュールであるscikit-learnは数多くの機械学習アルゴリズムをカンタンに使うことができることがわかりました。これまでは本ブログで紹介したのはいわゆる「教師あり学習」の問題が多かったのですが、今回は「教師なし」のアルゴリズムであるクラスタリングを行うこととしましょう。
ちなみに、教師あり、なしとはよく言いますが概要を述べると、教師あり学習は
教師あり学習(きょうしありがくしゅう, 英: Supervised learning)とは、機械学習の手法の一つである。事前に与えられたデータをいわば「例題(=先生からの助言)」とみなして、それをガイドに学習(=データへの何らかのフィッティング)を行うところからこの名がある。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
これに対して、教師なし学習は
教師なし学習(きょうしなしがくしゅう, 英: Unsupervised Learning)とは、機械学習の手法の一つである。「出力すべきもの」があらかじめ決まっていないという点で教師あり学習とは大きく異なる。データの背後に存在する本質的な構造を抽出するために用いられる。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
となります。つまり、「教師あり」とは正解がある場合です、例えば、「身長、体重、BMI、、」といったデータが有ったとして、これから「性別」を導きたいとすれば答えは「男、女」であり、これは教師あり学習となります。対して、「身長、体重、BMI、、」からいくつかの群に分割してみて、分割された群の傾向から「肥満」とか「ヤセ型」などの傾向を得る場合、これは教師なし学習となります。
言葉による説明はいささかイメージが湧きづらいかもしれませんので、実際にデータをいじってイメージを掴んでください。
※本記事の内容を実機で試してみたいという方は以下の記事を参考に開発環境をご準備ください
・Pythonやるならド定番!Anacondaをサクッと入れて巨人の肩に乗りましょう!
・Win10&Anaconda3環境でJupyter Notebookを起動してプログラムを実行する方法
・個人情報保護方針及び免責事項
k-meansでirisデータをクラスタリングする本記事の目的
本記事ではPythonの機械学習モジュールであるscikit-learnの中にあるクラスタリングのアルゴリズムであるk-meansを使って、毎度おなじみのirisデータセットをクラスタリングしてみます。クラスタリング及びk-meansの概要を掴んでおきましょう!
クラスタリング (英: clustering)、クラスタ解析(クラスタかいせき)、クラスター分析(クラスターぶんせき)は、データ解析手法(特に多変量解析手法)の一種。教師なしデータ分類手法、つまり与えられたデータを外的基準なしに自動的に分類する手法。また、そのアルゴリズム。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
前述の通り、教師なし分類法として与えられたデータを指定のクラスタに分類します。
k平均法(kへいきんほう、英: k-means clustering)は、非階層型クラスタリングのアルゴリズム。クラスタの平均を用い、与えられたクラスタ数k個に分類することから、MacQueen がこのように命名した。k-平均法(k-means)、c-平均法(c-means)とも呼ばれる。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
k-means(K平均法)はクラスタリングのアルゴリズムです。内容は数学的に厳密に定義されていますが、scikit-learnでは短いコードで実装することが可能です。
k-meansでirisデータをクラスタリングする処理の流れ
それでは処理の流れをご説明します!
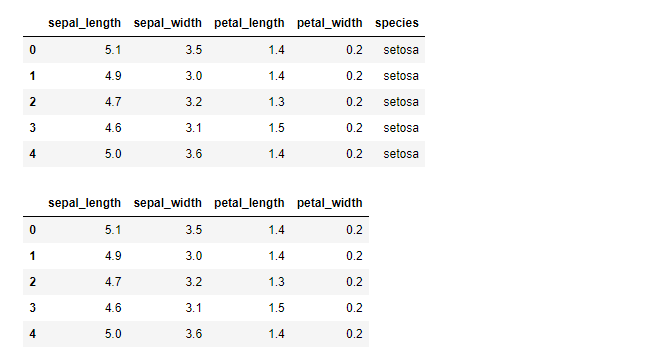
irisのデータセットをロードし、「種類」列を削除する
種類(species)の列を削除するのは、文字列であるため、クラスタリングで取り扱うことが出来ないからです。また、この列を削除することで、後に分類結果から面白いことがわかります。

実行結果です。種類(species)の列が削除されています。
KMeansをインポートし、分類するクラスタ数を指定して学習する
KMeansをインポートし、分類するクラスタ数を指定して学習します。
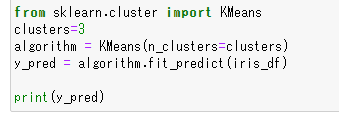
実行結果です。学習に基づいて予測した結果が配列で格納されています。

学習結果を散布図で表現してみる
学習結果を散布図で表現してみます。ここでalgorithm.cluster_centers_で各クラスタの中央を散布図に赤い点でプロットしてみます。

実行結果です。以下のような散布図が描けました。
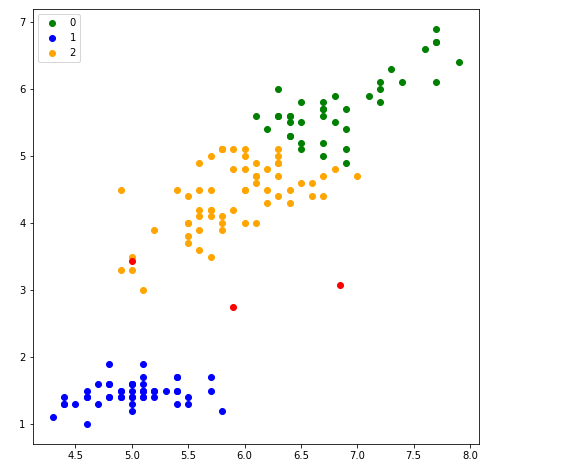
さて、この結果を踏まえて以下の点を検証してみましょう。
irisのデータセットを種類(species)別に散布図表現してみると…
上記のクラスタリング後の散布図とほぼ同じ散布図になりました。これは、k-meansにより3つのクラスタに分ける処理を行ったところ、元データの種別とほぼ同じ分類結果となったことを意味します。
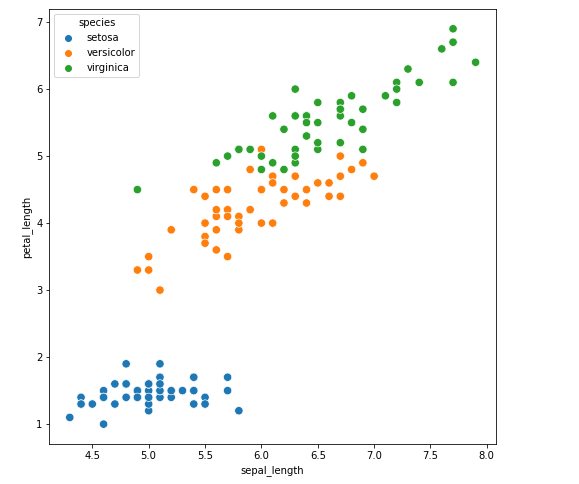
ちなみに最初のステップで種類(species)を削除してk-meansにデータを渡しましたので、k-meansは答えを知りません。いわゆる「教師なし学習」ですが、正解データに近い結果を得ることが出来ました。k-means優秀ですね!
k-meansでirisデータをクラスタリングするソースコード
それではサンプルコードをご紹介します!
データセットロードからk-meansによる学習
import seaborn as sns
iris_df = sns.load_dataset('iris') # データセットの読み込み
display(iris_df.head())
iris_df = iris_df.drop(['species'],axis=1)
display(iris_df.head())
print(iris_df.shape)
from sklearn.cluster import KMeans
clusters=3
algorithm = KMeans(n_clusters=clusters)
y_pred = algorithm.fit_predict(iris_df)
print(y_pred)
学習結果を散布図で表現する
centers = algorithm.cluster_centers_
plt.figure(figsize=(8,8))
plt.plot(centers[:,0],centers[:,1], 'o', color='red')
colors = ['green', 'blue', 'orange']
for p in set(y_pred):
idx = y_pred == p
plt.scatter(iris_df.loc[idx, 'sepal_length'], iris_df.loc[idx, 'petal_length'], label=str(p), c=colors[p])
plt.legend()
irisデータセットを種類別に散布図で表現する
import seaborn as sns
iris_df = sns.load_dataset('iris') # データセットの読み込み
import matplotlib.pyplot as plt
plt.figure(figsize=(8,8))
sns.scatterplot(x='sepal_length', y='petal_length', hue='species', s=70,
data=iris_df)
plt.show()
おわりに
本記事ではPythonの機械学習モジュールであるscikit-learnの中にあるクラスタリングのアルゴリズムであるk-meansを使って、irisデータセットをクラスタリングしてみました。irisデータセットの種類(species)を削除して学習しましたが、k-meansはほぼ正しい学習結果を得ることが出来ました。
さて、irisデータセットですが、種類を含めると5つの列がある5次元データです。このデータをアルゴリズムの中に入れて計算処理するのですが、これは3次元世界に住んでいる人間のアタマでは何をやっているかイメージすることは困難です。
次回はこの多次元データをもう少し人間の感覚的に理解しやすくなる「次元の圧縮」という方法をご紹介したいと思います。