

はじめに
オフィス業務で使うファイル形式として、Word、Excelなどのオフィスソフト系以外にPDFファイルも意外と使う頻度が高いのではないでしょうか?特に公共期間はPDFの利用率が多く、お役所の文書の多くはPDFに対応している事が多いと思います。
そうした使用頻度の多いPDFですが、編集には高価なPDF編集ソフトが必要でなかなか使いづらい側面があります。PDFファイルで渡された文書の内容を使って書類作成などすることもあると思いますが、最近はだいぶコピペしやすくなったとはいえ、いちいち全ファイルを開いて文書内容をコピーするのは大変です。
本記事ではこうしたPDFを使う上でネックになりそうな部分をPythonのPDFを扱うライブラリであるPDFMinerを使って解決したいと思います。
PDFMinerを使ってPDFファイルの内容を取得する本記事の目的
PDFMinerはPythonの数あるモジュールの中で、PDFを扱うのに特化したモジュールです。この他にもいくつかのPDFを扱うモジュールもあるのですが、動作が不安定だったりして心もとないものも多いです。本記事では、PDFMinerを使ってPythonからPDFファイルの内容を取得する方法を試します。しかし、PDFMinerは我々の開発環境として選んだAnacondaに含まれていないので、新たにインストールする必要があります。その方法は後ほどご説明します。
また、PDFMiner単体では文字列の入出力など、ファイル操作に必要な機能を完全にカバーできないのでStirngIOなど他のモジュールを使用することになります。プログラム初頭のImport文が大量になり、またパラメータを受け渡すオブジェクトが大量になりますが、最初はあまり構えず「魔法のおまじない」程度に考えてください。
PDFMinerを使ってPDFファイルの内容を取得する処理の流れ
それでは処理の流れを説明します。
pipコマンドでPDFMinerをインストールする
まずはpipコマンドを用いてPDFMinerをインストールしましょう。以下のコマンドをAnacondaプロンプトに入力してください。
>pip install pdfminer.six
Successfully installed pdfminer.six-〇〇 と表示されれば無事PDFMinerがインストールされました。
内容を取り出したいPDFファイルをプログラムと同一フォルダ内に用意する
今回はsampletxt.pdfというPDFファイルを同一フォルダに用意しました。
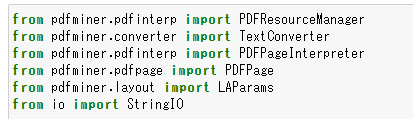
プログラム冒頭で各モジュールをインポートする
PDFの扱いは実は結構複雑なのでインポートするモジュールは複数になります。
各モジュールから作成したオブジェクトを用意する
複雑な処理に見えますが、一つのオブジェクトで処理を完了できないのでデータを経由する必要があるためやや冗長なコードとなっています。しかし、この処理を経ないと機能しないので割り切って手際よく処理しましょう。

PDFの内容を取得して表示する
極端に言えば、この部分のために前段のコードがあったようなものです。StringIO()のオブジェクトからgetValueで内容をcontentsに格納しています。そのご各オブジェクトをクローズし、最後にprint関数で取得した内容を表示しています。

そして実行結果はこちらです。
PDFMinerを使ってPDFファイルの内容を取得するサンプルコード
それではサンプルコードです!
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.layout import LAParams
from io import StringIO
f = open("sampletxt.pdf", 'rb')
outf = StringIO()
rm = PDFResourceManager()
lap = LAParams()
dev = TextConverter(rm, outf, laparams=lap)
iprtr = PDFPageInterpreter(rm, dev)
for page in PDFPage.get_pages(f):
iprtr.process_page(page)
contents = outf.getvalue()
outf.close()
dev.close()
f.close()
print(contents)
おわりに
本記事ではPDFMinerを使ってPDFファイルの内容を取得する方法をご紹介しました。サンプルコードをご覧なってお気づきと思いますが、冒頭のインポートおよび処理の上で必要になるオブジェクトの宣言とデータの流れが複雑なのでコードがあまり見やすいとは言い難い状態だと思います。しかし、これらのコードは初期に必要な手順と思ってコピペで使いまわしたりするのが正解だと思います。
PDFのモジュールなど、一部一般的でないファイルを扱うモジュールの中にはこうしたやや冗長なコードを書く必要があるものがありますので、マイナーな機能を使う場合はご注意ください。


