

はじめに
これまでにWebページの内容を取得するスクレイピングをPythonの様々なモジュールを使って実現する方法をご紹介してまいりました。これまで紹介したものは、取得するWebページのURLを指定してきましたが、普段使っているインターネットを考えてみても分かる通り、Webページに対して何らかの操作を行ってその結果表示される内容を取得したいこともあると思います。
こうした方法はこれまで見てきたurllibのrequestメソッドだけでは行うことができません。Webページの操作を行うブラウザをプログラム側から動かしてあげることで、取得したいページまでたどり着けるプログラムが必要となります。
本記事ではこのブラウザの自動操作を行うPythonモジュールMechanicalSoupをご紹介します。後ほどご説明しますが、このブラウザを自動化するモジュールには他にSeleniumというものもあるのですが、こちらは運用環境を選びますので、今回はMechanicalSoupをご案内したいと思います。
MechanicalSoupでブラウザ操作を自動化する本記事の目的
前述の通り、今回紹介するMechanicalSoupの他にブラウザを自動化するモジュールとしてseleniumというものがあります。Seleniumは開発や情報交換も活発なプロジェクトですが、windows環境で使用するにはやや不向きです。
理由としては、selenium自体がデスクトップの環境で使用するよりサーバーサイドなどで本格的なクローラやボットのようなものを作ることを想定されていることです。本ブログで推奨しているWin10+Anaconda3の環境では様々な制約から導入コストばかりが高くついて使いこなすのが難しいという難点があります。
それに対してMechanicalSoupはpipインストールすることで使うことができてお手軽です。さしあたってまずはこのMechanicalSoupを使ってブラウザをPython側から動かす方法を考えていきたいと思います。本記事では誰もが日常的に行っているであろうGoogle検索を自動化してみたいと思います。
MechanicalSoupでブラウザ操作を自動化する処理の流れ
それでは処理の流れを説明します!
まずはMechanicalSoupをpipインストールする
anacondaプロンプトに以下のコマンドを入力してください!
>pip install MechanicalSoup
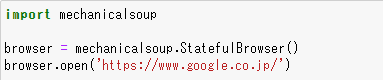
MechanicalSoupをインポートし、ブラウザオブジェクトを生成する
MechanicalSoupをインポートしたらブラウザを生成し、指定したURLを開きます。今回はGoolgの検索窓を開きます。
検索ボックスに検索語を入れて送信する
検索のformに検索語を入力して送信します。今回は「自動化ラボっ!」という弊サイトの名前を入力してみます。

Webページを抜き出してh3タグ(見出し)の内容を表示する
get_current_page()を使って検索結果に遷移したページの内容を取得します。取得したら検索結果の見出しであるh3タグの内容をprint関数で標準出力に表示します。

MechanicalSoupでブラウザ操作を自動化するソースコード
それではソースコードです!
注意!このコードを複数回実行するとGoogleからロボット判定されますのでくれぐれもご注意ください!
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open('https://www.google.co.jp/')
browser.select_form('form[action="/search"]')
browser['q'] = '自動化ラボっ!'
browser.submit_selected()
page = browser.get_current_page()
for a in page.select('h3 > a'):
print(a.text)
おわりに
本記事ではMechanicalSoupを使ったブラウザの自動操作をご紹介しました。今回Google検索を自動化しましたが、この処理をやりすぎるとGoogle側からロボット判定されますのでくれぐれもご注意ください。よく認証サイトでロボットか人間かをテストするパズルのような画面が表示される事があると思いますが、サイト側でもボットかどうかの取り締まりを行っているところがありますのでご注意ください!
今回のMechanicalSoupを使うことでログインが必要なページとか、あるいは各商品ページにアクセスしたい場合などにもアクセスすることができます。自動化操作の幅が広がるのではないでしょうか?



